Lenguajes
Ada

Historia: Ada es un lenguaje nacido de un proyecto en los 70s del ejército de los Estados Unidos, con la principal prioridad en la seguridad y la minimización de errores.
Concurrencia en el lenguaje: Sincroniza las tareas por rendez vous.
Herramientas para aprovechar la concurrencia: Amplio uso en la industria de las infraestructuras de riesgo grande, como sistemas de aviones, trenes, tanques y misiles.
Aplicaciones notables: Sistemas de planeación aérea y naval.
Haskell

Historia: Haskell es un lenguaje polimórficamente tipificado, perezoso, puramente funcional, muy diferente a la mayoría de los otros lenguajes de programación.
Concurrencia en el lenguaje: La concurrencia es "ligera", lo que significa que tanto la creación de hilos como los gastos generales de cambio de contexto son extremadamente bajos.
Herramientas para aprovechar la concurrencia: La programación de los hilos de Haskell se hace internamente y no hace uso de ningún paquete de hilos suministrado por el sistema operativo.
Aplicaciones notables: Análisis de sintaxis en código alojado en GitHub.
Erlang

Historia: Creado por Ericsson en 1986 con el propósito de desarrollar sistemas de telecomunicaciones. Diseñado para soportar numerosos procesos concurrentes. Liberado como software libre en 1998. A llevado al desarrollo de otros lenguajes que priorizan la concurrencia.
Concurrencia en el lenguaje: Modelo de concurrencia basado en actores, esto quiere decir que cuenta con procesos aislados que no comparten memoria, estos procesos se comunican a través de mensajes y son procesos ligeros gestionados por la máquina virtual BEAM.
Herramientas para aprovechar la concurrencia: Erlang ofrece diversas herramientas y bibliotecas que facilitan la gestión de la concurrencia y la construcción de sistemas distribuidos. La principal de estas es OTP (Open Telecom Platform) que proporciona componentes como supervisores, gen_servers, y otros patrones de diseño que facilitan la gestión de la concurrencia y la tolerancia a fallos.
- Supervisores: Procesos especiales que supervisan otros procesos
- Gen_servers: Gestionan el ciclo de vida de los procesos y la comunicación entre ellos.
Aplicaciones notables: Lógica de negocio de aplicaciones como WhatsApp.
Elixir

Historia: Elixir es un lenguaje de programación de propósito general, concurrente y funcional. Comenzó en 2011 con el objetivo de aprovechar la robustez y el rendimiento de Erlang y su máquina virtual, introduciendo características y mejoras que hicieran el lenguaje más productivo para los desarrolladores modernos, lo que lo ha hecho popular en el entorno de desarrollo web.
Concurrencia en el lenguaje: Al igual que Erlang, Elixir se basa en el modelo de actores y aprovecha la máquina virtual BEAM, ofreciendo aislamiento de procesos, comunicación mediante mensajes y la ligereza de los procesos.
Herramientas para aprovechar la concurrencia: Además de las herramientas OTP, podemos encontrar Phoenix Web Framework, capaz de manejar un alto tráfico concurrente y adecuado para aplicaciones con notificaciones en tiempo real; Task, para ejecutar funciones de forma concurrente; y Agent, para gestionar el estado compartido entre procesos.
Aplicaciones notables: Changelog, una plataforma de podcasts para desarrolladores.
Rust

Historia: Rust es un lenguaje de programación compilado, de propósito general y multiparadigma. Patrocinado por Mozilla desde 2009, Rust tiene como propósito ofrecer seguridad en memoria y concurrencia, diseñado específicamente para evitar problemas comunes como condiciones de carrera, desbordamiento de búfer y violaciones de acceso a memoria.
Concurrencia en el lenguaje: En el modelo de propiedad y préstamos de Rust, la propiedad asegura que solo un propietario pueda modificar un valor a la vez, mientras que los préstamos permiten el acceso seguro a datos compartidos. En cuanto a los tipos de concurrencia, Rust soporta concurrencia basada en hilos (threads) y basada en tareas asíncronas. Además, proporciona seguridad en la concurrencia al verificar las condiciones de seguridad en tiempo de compilación.
Herramientas para aprovechar la concurrencia: En Rust, std::thread permite crear y gestionar hilos de manera segura, mientras que std::sync proporciona primitivas de sincronización para manejar el acceso concurrente a los datos. Además, las funciones async/await facilitan la escritura de código asíncrono y concurrente.
Aplicaciones notables:
- Linux: Partes del kernel de Linux, cuya escritura es soportada desde octubre de 2022.
- Discord: Migró su servicio de "Read States" de Go a Rust para eliminar los picos de latencia causados por el Garbage Collector. [Referencia]
- Amazon Web Services: Uso de Rust en Firecracker y servicios centrales en la nube. [Referencia]
- Figma: Uso de Rust para cálculos intensivos y la infraestructura multijugador. [Referencia]
Ejemplo: Channels en Rust
Nota: Para entender el concepto general de Channels, visita la sección Conceptos → Mecanismos de Comunicación.
En Rust, los channels son mecanismos de comunicación entre hilos que permiten enviar y recibir datos
de forma segura en entornos concurrentes, evitando la necesidad de usar Mutex para compartir memoria directamente.
Sintaxis básica:
- Importar la librería estándar:
use std::sync::mpsc; - Crear un canal de comunicación:
mpsc::channel() - Enviar datos por el canal:
send(T) - Recibir datos del canal:
recv()
Ejemplo Práctico: Sistema de Monitoreo de Sensores
Este ejemplo demuestra cómo dos sensores (temperatura y humedad) envían datos concurrentemente a un hilo central de monitoreo usando channels.
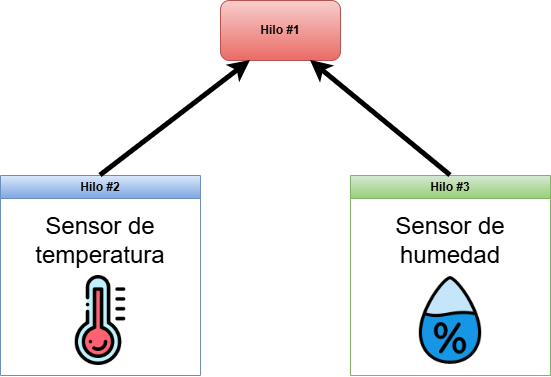
Código:
use std::sync::mpsc;
use std::thread;
use std::time::Duration;
fn sensor_temperatura(tx: mpsc::Sender<(String, i32)>) {
let temperaturas = [22, 24, 27, 31, 29];
for temp in temperaturas {
println!("[Sensor Temperatura {:?}] Nueva lectura: {}°C",
thread::current().id(), temp);
tx.send(("Temperatura".to_string(), temp)).unwrap();
thread::sleep(Duration::from_millis(700));
}
}
fn sensor_humedad(tx: mpsc::Sender<(String, i32)>) {
let humedades = [40, 45, 50, 48, 43];
for hum in humedades {
println!("[Sensor Humedad {:?}] Nueva lectura: {}%",
thread::current().id(), hum);
tx.send(("Humedad".to_string(), hum)).unwrap();
thread::sleep(Duration::from_millis(500));
}
}
fn main() {
let (tx, rx) = mpsc::channel();
// Sensor temperatura
let tx_temp = tx.clone();
let h1 = thread::spawn(move || {
sensor_temperatura(tx_temp);
});
// Sensor humedad
let tx_hum = tx.clone();
let h2 = thread::spawn(move || {
sensor_humedad(tx_hum);
});
// Cerrar sender principal
drop(tx);
// Centro de monitoreo
for (tipo, valor) in rx {
println!("[CENTRAL] Dato recibido -> {}: {}", tipo, valor);
}
h1.join().unwrap();
h2.join().unwrap();
println!("--- Monitoreo finalizado ---");
}Explicación del Código:
- Creación del canal:
mpsc::channel()crea un canal de comunicación múltiple productor, único consumidor. - Clonación del transmisor:
tx.clone()permite que múltiples hilos envíen datos por el mismo canal. - Hilos concurrentes: Cada sensor se ejecuta en su propio hilo, enviando datos independientemente.
- Comunicación segura: Los datos se envían sin necesidad de locks o mutex explícitos.
- Recepción centralizada: El hilo principal recibe todos los mensajes en orden de llegada.
Salida de Ejecución:
[Sensor Humedad ThreadId(3)] Nueva lectura: 40% [Sensor Temperatura ThreadId(2)] Nueva lectura: 22°C [CENTRAL] Dato recibido -> Humedad: 40 [CENTRAL] Dato recibido -> Temperatura: 22 [Sensor Humedad ThreadId(3)] Nueva lectura: 45% [CENTRAL] Dato recibido -> Humedad: 45 [Sensor Temperatura ThreadId(2)] Nueva lectura: 24°C [CENTRAL] Dato recibido -> Temperatura: 24 [Sensor Humedad ThreadId(3)] Nueva lectura: 50% [CENTRAL] Dato recibido -> Humedad: 50 [Sensor Temperatura ThreadId(2)] Nueva lectura: 27°C [CENTRAL] Dato recibido -> Temperatura: 27 [Sensor Humedad ThreadId(3)] Nueva lectura: 48% [CENTRAL] Dato recibido -> Humedad: 48 [Sensor Humedad ThreadId(3)] Nueva lectura: 43% [CENTRAL] Dato recibido -> Humedad: 43 [Sensor Temperatura ThreadId(2)] Nueva lectura: 31°C [CENTRAL] Dato recibido -> Temperatura: 31 [Sensor Temperatura ThreadId(2)] Nueva lectura: 29°C [CENTRAL] Dato recibido -> Temperatura: 29 --- Monitoreo finalizado ---
Observaciones Clave:
- Los sensores operan concurrentemente con diferentes velocidades (700ms vs 500ms).
- Los mensajes llegan a la central en el orden en que son enviados, no necesariamente en orden de sensor.
- El sensor de humedad es más rápido, por lo que envía más datos en menos tiempo.
- No hay condiciones de carrera gracias al sistema de ownership de Rust.
- La comunicación es type-safe: solo se pueden enviar tuplas
(String, i32).
Ventajas de usar Channels:
- Seguridad: Sin data races ni condiciones de carrera
- Simplicidad: No requiere locks o mutex explícitos
- Escalabilidad: Múltiples productores, un consumidor
- Type-Safe: Verificación de tipos en compilación
GO

Historia: Diseñado en Google en 2007, Go (también conocido como Golang) tenía como objetivo combinar lo mejor de los lenguajes compilados, como la eficiencia y la seguridad, con las ventajas de los lenguajes interpretados, como la facilidad de uso y la productividad. Hoy en día, Go es popular en sistemas distribuidos, microservicios y aplicaciones en la nube
Concurrencia y herramientas en el lenguaje: En Go, las goroutines son funciones que se ejecutan concurrentemente en el mismo espacio de direcciones y son gestionadas por el runtime de Go. Los canales permiten la comunicación y sincronización entre goroutines, pudiendo ser sincrónicos o asincrónicos.
Aplicaciones notables: El código backend de Uber.
Crystal
Historia: Crystal es uno de los nuevos lenguajes en la escena, iniciado en 2012. Tiene una sintaxis similar a Ruby, estáticamente tipado, compilado y es self-hosted (Crystal está escrito en Crystal).
Concurrencia en el lenguaje: Crystal viene con una primitiva de concurrencia llamada fibras, que son básicamente una versión más ligera de hilos. Las otras primitivas de concurrencia son canales.
Herramientas para aprovechar la concurrencia: Utiliza canales para la concurrencia, similar a Go.
Aplicaciones notables: Servicios web de compañías como Errordeck, GigSmart, Appmonitor, etc.
Java

Historia: Java es un lenguaje de programación orientado a objetos creado en 1991 y publicado en 1995 por Sun Microsystem (adquirida por Oracle en 2010), con la intención de que los programadores escribieran el código solo una vez y lo ejecutaran en cualquier dispositivo.
Concurrencia en el lenguaje: Java permite realizar concurrencia con la librería threads. Además, cuenta con otras librerías que implementan métodos de planificación y control de procesos (variables atómicas, semáforos, entre otros) traídos del paquete concurrent.
Aplicaciones notables: Innumerables. Desde servicios web backend mediante Spring Boot hasta desarrollo de videojuegos con LWJGL, la librería usada para escribir Minecraft.
Python

Historia: Python es el lenguaje más utilizado a nivel mundial (según revista IEEE). Es un lenguaje de sintaxis simple y cubre una gran cantidad de áreas del conocimiento como inteligencia artificial y ciencia de datos.
Concurrencia en el lenguaje: Cuenta con varias librerías para la implementación de programación concurrente y su respectivo control, como lo son la librería "Thread" y "Multiprocessing".
Herramientas para aprovechar la concurrencia: La librería "Thread" incluye una interfaz de alto nivel orientada a objetos para trabajar con concurrencia desde Python. Los objetos Thread se ejecutan al mismo tiempo dentro del mismo proceso y comparten memoria.
Aplicaciones notables: El backend de Instagram.
C

Historia: C es uno de los lenguajes más rápidos que existen puesto a que es un lenguaje compilado. Es altamente usado en el diseño y desarrollo de los sistemas operativos que hoy en día se usan.
Concurrencia en el lenguaje: En cuanto a programación concurrente, usa la librería pthread.h para la creación de hilos y métodos de control muy básicos como la implementación de un semáforo.
Aplicaciones notables: El kernel de Linux y otros lenguajes como Python y C++.
C++

Historia: Fue diseñado a mediados de los años 80 por el danés Bjarne Stroustrup. Su intención fue la de extender el lenguaje de programación C para que tuviese los mecanismos necesarios para manipular objetos.
Concurrencia en el lenguaje: C++ contiene los paradigmas de la programación estructurada y orientada a objetos. Se puede usar una librería thread que es básicamente una sección de código independiente que el procesador puede ejecutar de forma concurrente junto a otros threads o hilos de ejecución.
Aplicaciones notables: Motores gráficos como Source de Valve, usado en videojuegos como Half-Life y Counter-Strike.
Ejemplos Lenguajes
Python
from threading import Thread
import time
def say_hello(name):
print (name, "Hola")
t = Thread(target=say_hello, args=("world",))
t.start()
t.join()
Ejecucion: python archivo.py
('world', 'Hola')
Go:
En este ejemplo podemos visualizar que los hilos no se ejecutan en el orden ascedente si no esto lo decide el scheduler del sistema operativo
package main
import (
"fmt"
"time"
)
const FINAL = 100 * time.Millisecond
func saluda(i int) {
time.Sleep(10 * time.Duration(i%5) * time.Millisecond)
fmt.Println("Hola a todos", i)
}
func main() {
for i := 1; i <= 6; i++ {
// Lanzamos nuestro hilo solo anteponiendo la palabra go a la funcion
go saluda(i)
}
time.Sleep(FINAL)
}
Ejecucion: go run archivo.go
Hola a todos 5
Hola a todos 6
Hola a todos 1
Hola a todos 2
Hola a todos 3
Hola a todos 4
C:
El siguiente código fuente implementa un semáforo y solo sirve sistemas operativos basado en unix.
#include <stdlib.h>
#include <stdio.h>
#include <pthread.h>
#include <unistd.h>
#include <sys/types.h>
#include <fcntl.h>
#include <sys/stat.h>
#include <semaphore.h>
#define NUMHILOS 5
sem_t *semaforo;
int error, i, parametro, a;
char t;
void *z;
void *fun(void *ap )
{
sem_t *sem = ap;
char t;
sem_wait( sem ); // Bloqueamos seccion critica
printf( "\n Hilo ENTRO a seccion critica" );
fflush( stdout );
sleep( 1 );
printf( "\n Hilo SALIO a seccion critica\n\n" );
fflush( stdout );
sem_post( sem ); // Desbloqueamos seccion critica
}
int main()
{
// Creamos nuestro semaforo
semaforo = sem_open( "sema", O_CREAT, 0666, 1 );
// Declaramos el descritor de los hilos
pthread_t hilos[NUMHILOS];
// Creamos nuestros hilos
for( i = 0; i < NUMHILOS; i++ )
pthread_create( &hilos[i], NULL, (void *)fun, semaforo );
// Esperamos a que nuestro hilos de ejecutan antes de terminar el programa
for( i = 0; i < NUMHILOS; i++ )
pthread_join( hilos[i], (void *)&z );
// Destruimos nuestro semaforo
sem_unlink( "sema" );
sem_close( semaforo );
return 0;
}
Compilamos: gcc semaforo.c -o semaforo -pthread
Ejecutamos: ./semaforo
Hilo ENTRO a sección critica
Hilo SALIO a sección critica
Hilo ENTRO a sección critica
Hilo SALIO a sección critica
Hilo ENTRO a sección critica
Hilo SALIO a sección critica
C++:
Calculamos el numero pi con 4 hilos con la ayuda de Serie de Leibniz
#include <iostream>
#include <thread>
#include <vector>
using namespace std;
vector<double> valorCal(4, 0.0), limites;
void calcularIntervalo(int index) {
for (int i = limites[index]; i < limites[index + 1]; i++)
if (i % 2 == 0)
valorCal[index] += 1.0 / (2 * i + 1);
else
valorCal[index] -= 1.0 / (2 * i + 1);
}
int main() {
// Creamos nuestro limites
int numeroSerie = 1000000000;
limites.push_back(0);
limites.push_back(numeroSerie / 4);
limites.push_back(numeroSerie / 2);
limites.push_back(3 * (numeroSerie / 4));
limites.push_back(numeroSerie);
// Creamos a hilos
thread hilos[4];
// Inicializamos nuestros hilos
for (int i = 0; i < 4; i++)
hilos[i] = thread(calcularIntervalo, i);
// Esperemos a que nuestros hilos terminen
for (int i = 0; i < 4; i++)
hilos[i].join();
// Calculamos nuestra respuesta
double answer = 0;
for (int i = 0; i < 4; i++) answer += valorCal[i];
answer *= 4;
printf("EL valor de pi es:\t%.20f\n", answer);
return 0;
}
Compilar: g++ pi.cpp -o pi -std=c++11 -pthread
Ejecutar: ./pi
EL valor de pi es: 3.14159265258921038821
Java
Un grupo de personas trata de ir de una isla(Oahu) a la otra(Molokai) con un solo bote.

Reglas:
- Cada persona es un hilo.
- La persona puede ser un adulto o un niño.
- Pueden ir dos niños en el bote o solo un adulto.
- El bote necesita como mínimo un piloto./li>
- las personas solo se pueden comunicar con los que estén en la misma isla.
- Siempre hay mínimo dos niños.
El principal objetivo del ejemplo es mostrar la sincronización de los hilos, la solución al problema consiste en llevar dos niños a Molokai, hacer que uno se devuelva con el bote, subir un adulto en oahu, cuando este llegue a Molokai se devolverá el otro niño que estaba ahí, y en Oahu se volverán a subir dos niños, este proceso se repetirá hasta que todas las personas estén en Oahu, hay que tener en cuenta que no hay algo como unidad principal que controle cuando pasará cada persona, cada hilo deberá saber cuando ejecutar sus instrucciones dependiendo de la sincronización con los otros
import java.util.concurrent.Semaphore;
//extiende de thread y sobreescribe run sin nada
public class Persona extends Thread{
int Tamano;
String ubicacion;
static String boatUbication="Oahu";
public static String getBoatUbication() {
return boatUbication;
}
public static void setBoatUbication(String boatUbication) {
Persona.boatUbication = boatUbication;
}
public Persona(int tamano, String ubicacion) {
super();
this.Tamano = tamano;
this.ubicacion = ubicacion;
}
@Override
public void run() {
//Intencionalmente vacío
}
}
import java.util.logging.Level;
import java.util.logging.Logger;
//extiende de persona
public class Adult extends Persona {
public Adult() {
super(2, "Oahu");
}
//sobreescribe run
@Override
public void run() {
//mientras no hayan pasado todas las personas
while(Boat.ContMolokai < Boat.ContTotalPersonas){
try {
//semaforo encargado de que un niño y adulto no luchen por el bote
Boat.classExclus.acquire();
if (this.ubicacion.equals("Oahu") && boatUbication.equals(this.ubicacion) && Boat.ContChildBack%2!=0 && Boat.ContAdultOahu != 0){
//si ve que puede pasar lo hace, adquiere las dos posiciones del bote
Boat.available.acquire();
Boat.available.acquire();
Boat.bg.AdultRowToMolokai();
this.ubicacion="Molokai";
boatUbication="Molokai";
Boat.ContMolokai++;
Boat.ContOahu--;
Boat.ContAdultOahu--;
//al llegar libera las dos posiciones del bote
Boat.available.release();
Boat.available.release();
}
Boat.classExclus.release();
} catch (InterruptedException ex) {
Logger.getLogger(Child.class.getName()).log(Level.SEVERE, null, ex);
}
}
}
}
import java.util.concurrent.Semaphore;
import java.util.logging.Level;
import java.util.logging.Logger;
// parecida a Adult
public class Child extends Persona {
public Child() {
super(1, "Oahu");
}
@Override
public void run() {
while (Boat.ContMolokai < Boat.ContTotalPersonas) {
try {
Boat.classExclus.acquire();
if (this.ubicacion.equals("Oahu")
&& boatUbication.equals(this.ubicacion)
&& (Boat.ContChildBack % 2 == 0
|| Boat.ContAdultOahu == 0)) {
// a diferencia del adulto el niño solo adquiere una
// posicion del bote
Boat.available.acquire();
Boat.UbicacionDispon--;
if (Boat.UbicacionDispon == 1)
Boat.bg.ChildRowToMolokai();
this.ubicacion = "Molokai";
Boat.ContMolokai++;
Boat.ContOahu--;
if (Boat.UbicacionDispon == 0) {
Boat.bg.ChildRideToMolokai();
boatUbication = "Molokai";
Boat.UbicacionDispon = 2;
}
Boat.available.release();
}
// parte de la seccion critica encargada de que el niño regrese
// desde Molokai a Oahu
if (this.ubicacion.equals("Molokai")
&& boatUbication.equals(this.ubicacion)
&& (Boat.ContMolokai < Boat.ContTotalPersonas)) {
// para evitar que se regresen dos niños el niño adquiere
// las dos posiciones del bote
Boat.available.acquire();
Boat.available.acquire();
Boat.bg.ChildRowToOahu();
this.ubicacion = "Oahu";
boatUbication = "Oahu";
Boat.ContMolokai--;
Boat.ContOahu++;
Boat.ContChildBack++;
// llega y libera las dos posiciones
Boat.available.release();
Boat.available.release();
}
Boat.classExclus.release();
} catch (InterruptedException ex) {
Logger.getLogger(Child.class.getName())
.log(Level.SEVERE, null, ex);
}
}
}
}
import java.util.Scanner;
import java.util.concurrent.Semaphore;
import java.util.LinkedList;
public class Boat {
//se instancian los dos semaforos
public static Semaphore available = new Semaphore(2, true);
public static Semaphore classExclus = new Semaphore(1, true);
static Scanner sc = new Scanner(System.in);
//contadores para la comunicacion
static int childrenTot=0;
static int adultTot=0;
static int ContChilds=0;
static int ContAdults=0;
static int ContTotalPersonas=0;
static int ContOahu=0;
static int ContMolokai=0;
static int ContAdultOahu=0;
static int UbicacionDispon=2;
static int ContChildBack=0;
//arreglo de personas
static LinkedList ChildList = new LinkedList();
static LinkedList AdultList = new LinkedList();
static BoatGrader bg= new BoatGrader();
//se crean los hilos
static public void begin(){
for(Child element : ChildList){
element.start();
}
for(Adult element : AdultList){
element.start();
}
//al terminar los hilos hacen join con el hilo principal
for(Child element : ChildList){
try {
element.join();
} catch (InterruptedException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
}
for(Adult element : AdultList){
try {
element.join();
} catch (InterruptedException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
}
}
public static void main(String args[]) {
//entradas del programa
while (childrenTot< 2){
System.out.println("Introduzca el numero de niños (mayor a 1): ");
childrenTot=sc.nextInt();
}
System.out.println("Introduzca el numero de adultos: ");
adultTot=sc.nextInt();
for (int i=0;i< childrenTot;i++){
ChildList.add(new Child());
ContChilds++;
}
for (int i=0;i< adultTot;i++){
AdultList.add(new Adult());
ContAdults++;
}
ContTotalPersonas=ContChilds+ContAdults;
ContAdultOahu=ContAdults;
ContOahu=ContTotalPersonas;
Boat.begin();
System.out.println("llegaron "+ContMolokai+" personas");
}
}
Ejecución:
Introduzca el numero de niños (mayor a 1):
3
Introduzca el numero de adultos:
5
**Child rowing to Molokai.
**Child arrived on Molokai as a passenger.
**Child rowing to Oahu.
**Adult rowing to Molokai.
**Child rowing to Oahu.
**Child rowing to Molokai.
**Child arrived on Molokai as a passenger.
**Child rowing to Oahu.
**Adult rowing to Molokai.
**Child rowing to Oahu.
**Child rowing to Molokai.
**Child arrived on Molokai as a passenger.
**Child rowing to Oahu.
**Adult rowing to Molokai.
**Child rowing to Oahu.
**Child rowing to Molokai.
**Child arrived on Molokai as a passenger.
**Child rowing to Oahu.
**Adult rowing to Molokai.
**Child rowing to Oahu.
**Child rowing to Molokai.
**Child arrived on Molokai as a passenger.
**Child rowing to Oahu.
**Adult rowing to Molokai.
**Child rowing to Oahu.
**Child rowing to Molokai.
**Child arrived on Molokai as a passenger.
**Child rowing to Oahu.
**Child rowing to Molokai.
**Child arrived on Molokai as a passenger.
llegaron 8 personas
Go:
package main
import (
"fmt"
"time"
)
func main() {
fmt.Println("iniciando")
go printForward()
go printBackwards()
time.Sleep(time.Second * 5)
fmt.Println("terminando")
}
func printForward() {
for i := 0; i < 10; i++ {
fmt.Println(i)
time.Sleep(time.Millisecond)
}
}
func printBackwards() {
for i := 10; i <= 20; i++ {
fmt.Println(i)
time.Sleep(time.Millisecond)
}
}
En Go tenemos rutinas que tienen su propio stack, aunque estos no son hilos como tal, pero si se pueden aprovechar de esta forma
package main
import(
"fmt"
"time"
)
func main() {
c := make(chan string)
go echo(c)
c < - "Hola"
mensaje := < - c
fmt.Println(mensaje)
}
func echo(c chan string) {
msg := < - c
time.Sleep(time.Second * 1)
c < - fmt.Sprintf("Mensaje recibido: %s", msg)
}
salida= Mensaje recibido:Hola
En Go tenemos el Select es como un switch, pero que espera mensajes en canales. Su finalidad es comunicar, no comparar valores.
package main
import(
"fmt"
"time"
)
func main() {
process1 := processExpensiveTransaction()
process2 := processExpensiveTransaction()
for i := 0; i < 2; i++ {
select {
case msg1 := <- process1:
fmt.Println("Proceso 1 termino con status ", msg1)
case msg2 := <- process2:
fmt.Println("Proceso 2 termino con status ", msg2)
}
}
}
func processExpensiveTransaction() chan string {
c := make(chan string)
go func() {
time.Sleep(time.Duration(rand.Intn(6)) * time.Second)
c <- "ok"
} ()
return c
}
- Otro Ejemplo en Go:
En este ejemplo vamos a optimizar una aplicación que realiza peticiones http, haciendo uso de concurrencia, el siguiente código es la aplicación implementada de manera secuencial:
package main
import (
"fmt"
"log"
"net/http"
"os"
)
func sendRequest(url string){
res, err := http.Get(url)
if err != nil{
panic(err)
}
fmt.Printf("Estado: %d URL: %s\n", res.StatusCode,url)
}
func main() {
if len(os.Args) < 2 {
log.Fatalln("Uso: go run main.go url1 url2 .. urln")
}
for _, url := range os.Args[1:] {
sendRequest("https://" + url)
}
}
Para hacer uso del programa, usamos el siguiente comando:
go run main.go url1 url2 .. urln
Donde url1 a urln se reemplazan por urls a las cuales queremos hacer la petición Get.
Los resultados de esto deberían ser los siguientes, en el caso de haber usado las urls de google, youtube y
facebook:
Estado: 200 URL: https://facebook.com Estado: 200 URL: https://youtube.com Estado: 200 URL: https://google.com
Para medir el tiempo de ejecución se debe usar el siguiente comando:
Para Windows:
Measure-Command {go run main.go url1 url2 .. urln}
Para Linux:
time go run main.go url1 url2 .. urln
Este tiempo de ejecución es importante para comparar el antes y el después de usar concurrencia. Haciendo
uso del comando de Windows, obtuvimos como resultado:
Days : 0 Hours : 0 Minutes : 0 Seconds : 1 Milliseconds : 970 Ticks : 19702343 TotalDays : 2,28036377314815E-05 TotalHours : 0,000547287305555556 TotalMinutes : 0,0328372383333333 TotalSeconds : 1,9702343 TotalMilliseconds : 1970,2343
Actualmente nuestra aplicación funciona de manera síncrona, lo cual ralentiza su procesamiento, debido a que tiene que esperar que cada petición termine para poder realizar la siguiente. Ahora vamos a modificar este programa inicial para usar concurrencia y optimizar nuestra aplicación:
package main
import (
"fmt"
"log"
"net/http"
"os"
)
func sendRequest(url string){
res, err := http.Get(url)
if err != nil{
panic(err)
}
fmt.Printf("Estado: %d URL: %s\n", res.StatusCode,url)
}
func main() {
if len(os.Args) < 2 {
log.Fatalln("Uso: go run main.go url1 url2 .. urln")
}
for _, url := range os.Args[1:] {
go sendRequest("https://" + url)
}
}
Con solo agregar la palabra go, hacemos que cada consulta se ejecute en goroutines separadas y si ejecutamos el comando de Benchmark anteriormente mencionado vamos a observar que el tiempo de ejecucion es mucho menor:
Days : 0 Hours : 0 Minutes : 0 Seconds : 0 Milliseconds : 832 Ticks : 8328442 TotalDays : 9,63940046296296E-06 TotalHours : 0,000231345611111111 TotalMinutes : 0,0138807366666667 TotalSeconds : 0,8328442 TotalMilliseconds : 832,8442
Pero nos vamos a encontrar con un problema: no se imprimen los resultados de las goroutines en consola. Para corregir esto vamos a hacer uso de WaitGroup, el cual ayuda a contabilizar las rutinas que se tienen activas:
package main
import (
"fmt"
"log"
"net/http"
"os"
)
var wg sync.WaitGroup
func sendRequest(url string){
defer wg.Done() //Decrementa el contador de goroutines
res, err := http.Get(url)
if err != nil{
panic(err)
}
fmt.Printf("Estado: %d URL: %s\n", res.StatusCode,url)
}
func main() {
if len(os.Args) < 2 {
log.Fatalln("Uso: go run main.go url1 url2 .. urln")
}
for _, url := range os.Args[1:] {
go sendRequest("https://" + url)
wg.Add(1) //Incrementa el contador de goroutines
}
wg.Wait() //Indica que toca esperar a que todas las goroutines terminen
}
Si ejecutamos de nuevo nuestro programa, vamos a ver que los resultados ahora si se muestran en consola.
Estado: 200 URL: https://facebook.com
Estado: 200 URL: https://youtube.com
Estado: 200 URL: https://google.com
Es posible que las goroutines se mezclen en consola, debido a que pueden terminar al mismo tiempo. Dando como resultado:
Estado: 200 URL: Estado: 200 URL: https://youtube.comhttps://facebook.com
Estado: 200 URL: https://google.com
Para evitar que esto ocurra vamos a hacer uso de Mutex, el cual ayuda a sincronizar el acceso a recursos compartidos, como es el caso de la consola. Para hacer uso de Mutex, hacemos lo siguiente:
package main
import (
"fmt"
"log"
"net/http"
"os"
)
var wg sync.WaitGroup
var mut sync.Mutex
func sendRequest(url string){
defer wg.Done() //Decrementa el contador de goroutines
res, err := http.Get(url)
if err != nil{
panic(err)
}
mut.Lock() //Bloquea el recurso inferior para que solo esta gorutine
//pueda hacer uso de este
defer mut.Unlock() //Desbloquea el recursos despues de haber terminado de usarlo
fmt.Printf("Estado: %d URL: %s\n", res.StatusCode,url)
}
func main() {
if len(os.Args) < 2 {
log.Fatalln("Uso: go run main.go url1 url2 .. urln")
}
for _, url := range os.Args[1:] {
go sendRequest("https://" + url)
wg.Add(1) //Incrementa el contador de goroutines
}
wg.Wait() //Indica que toca esperar a que todas las goroutines terminen
}
Erlang:
La función spawn en Erlang nos permite crear un proceso en paralelo.
-module(helloworld).
-export([start/0]).
start() ->
Pid = spawn(fun() -> server("Hello") end),
server(Message) ->
io:fwrite("~p",[Message]).
La salida es la siguiente:
"Hello"
El operador ! nos permite enviar mensajes a los procesos.
-module(helloworld).
-export([start/0]).
start() ->
Pid = spawn(fun() -> server("Hello") end),
Pid ! {hello}.
server(Message) ->
io:fwrite("~p",[Message]).
La salida es la siguiente:
"Hello"
receive permite recibir mensajes que son enviados a los procesos.
-module(helloworld).
-export([loop/0,start/0]).
loop() ->
receive
{rectangle, Width, Ht} ->
io:fwrite("Area of rectangle is ~p~n" ,[Width * Ht]),
loop();
{circle, R} ->
io:fwrite("Area of circle is ~p~n" , [3.14159 * R * R]),
loop();
Other ->
io:fwrite("Unknown"),
loop()
end.
start() ->
Pid = spawn(fun() -> loop() end),
Pid ! {rectangle, 6, 10},
Pid ! {circle, 6},
Pid ! {square, 4, 4}.
La salida es la siguiente:
Area of rectangle is 60
Area of circle is 113.09723999999999
Unknown
Rust:
Rust facilita la programación concurrente con las comprobaciones que se hacen en tiempo de compilación y con la gestión de memoria que realiza.
Hilos: creamos hilos con el comando thread::spawn, que recibe un closure y se lanza justo al definirlo.
use std::thread;
fn main() {
let child = thread::spawn(|| {
println!("Hello from a thread!");
});
let _ = child.join();
}
La salida es la siguiente:
Hello from a thread!
Para esperar a que un hilo termine se puede utilizar el método join.
Podemos lanzar varios hilos dentro de un bucle
Aquí, en cada vuelta del bucle, iniciaremos un hilo con un iterador asociado. El primer hilo se inicia con el número 0, el segundo con el número 1 y así sucesivamente. Podemos ver en el resultado lo que se dijo antes: los subprocesos se lanzaron en un orden específico y, sin embargo, al mostrar los resultados, vemos que está completamente desordenado: de hecho, la velocidad de la ejecución de cada uno de los hilos variará. Si reiniciamos este programa, su salida y la visualización de los números serán diferentes; es imposible de predecir el orden de los números que aparecerán. Pero, si utilizamos el sistema de bloqueo y desbloqueo, para que cada hilo espere hasta que el anterior termine, el orden será perfecto.
use std::thread;
fn main() {
let mut childs = vec![];
for i in 0..10 {
let child = thread::spawn(move || {
println!("Hello from a thread! {}", i);
});
childs.push(child);
}
for c in childs {
let _ = c.join();
}
}
La salida es la siguiente:
Hello from a thread! 1
Hello from a thread! 0
Hello from a thread! 5
Hello from a thread! 3
Hello from a thread! 7
Hello from a thread! 4
Hello from a thread! 8
Hello from a thread! 6
Hello from a thread! 2
Hello from a thread! 9
Mutex y Arc: Para compartir una referencia a memoria entre hilos se usa Arc y Mutex en combinación. Arc es un contador de referencias que se puede compartir entre hilos. Mutex implementa el bloqueo asociado a la variable en concreto.
use std::thread;
use std::sync::{Arc, Mutex};
fn main() {
let mut childs = vec![];
let shared = Arc::new(Mutex::new(String::from("")));
for i in 0..10 {
let s = shared.clone();
let child = thread::spawn(move || {
println!("In thread {}", i);
let out = String::from("Thread ") + &i.to_string() + "\n";
s.lock().unwrap().push_str(&out);
});
childs.push(child);
}
for c in childs {
let _ = c.join();
}
println!("\nOutput:\n{}", *(shared.lock().unwrap()));
}
La salida es la siguiente:
In thread 0
In thread 3
In thread 5
In thread 4
In thread 2
In thread 6
In thread 7
In thread 8
In thread 1
In thread 9
Output:
Thread 0
Thread 3
Thread 5
Thread 4
Thread 2
Thread 6
Thread 7
Thread 8
Thread 1
Thread 9
En este ejemplo se define la cadena dentro de un Mutex y este dentro de un Arc, así se comparte la memoria
entre hilos.
channel crea un transmisor, tx, y un receptor, rx, en cada hilo, clona el transmisor y escribe en este la
salida. En el send se puede enviar cualquier tipo de dato según se cree el channel, no se pueden enviar
diferentes tipos de datos por el mismo canal.
use std::thread;
use std::sync::mpsc;
fn main() {
let (tx, rx) = mpsc::channel();
let mut childs = vec![];
for i in 0..10 {
let tx = tx.clone();
let child = thread::spawn(move || {
println!("In thread {}", i);
let out = String::from("Thread ") + &i.to_string();
tx.send(out).unwrap();
});
childs.push(child);
}
for c in childs {
let _ = c.join();
}
println!("\nOutput:");
loop {
match rx.try_recv() {
Ok(x) => println!("{}", x),
Err(_) => break
}
}
}
La salida es la siguiente:
In thread 0
In thread 2
In thread 1
In thread 4
In thread 5
In thread 6
In thread 3
In thread 8
In thread 7
In thread 9
Output:
Thread 0
Thread 2
Thread 1
Thread 4
Thread 5
Thread 6
Thread 8
Thread 7
Thread 9
Thread 3
Ejemplo Manejo de Hilos en RUST:
Este programa crea 10 tareas concurrentes utilizando thread::spawn, donde cada tarea alterna entre esperar datos (I/O simulado) con thread::sleep y realizar cálculos pesados de CPU. En una máquina con 1 núcleo físico y 2 hilos de hardware, aunque se creen 10 threads, el procesador solo puede ejecutar aproximadamente 2 tareas al mismo tiempo.
¿Qué demuestra el ejemplo?
Concurrencia: muchas tareas progresan al mismo tiempo.
Paralelismo: limitado por la cantidad de hilos físicos y lógicos disponibles.
Mientras una tarea está bloqueada esperando I/O, otra puede usar el CPU.
El sistema operativo intercambia constantemente los threads activos para aprovechar mejor el procesador.
Idea clave: crear muchos threads no significa que todos se ejecuten físicamente al mismo tiempo. La concurrencia permite administrar múltiples tareas de forma eficiente, mientras que el paralelismo real depende del hardware disponible.

Ejecución secuencial
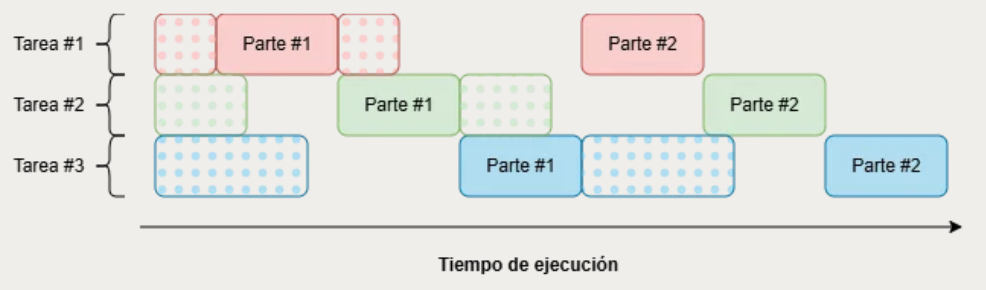
Ejecución concurrente
Código:
use std::thread;
use std::time::{Duration, Instant};
fn calculo_pesado(limite: u64) {
let mut acumulador: f64 = 0.0;
for i in 0..limite {
acumulador = acumulador * (i as f64);
}
}
fn ejecutar_tarea(i: u64, n_partes: u64, carga: u64) {
for j in 0..n_partes {
// --- Simulando operacion I/O ---
println!("Tarea {:02} [{:?}] -> Requiriendo datos en disco", i, thread::current().id());
thread::sleep(Duration::from_millis((100 * i * (n_partes - j)) % 10000));
// --- PARTE n ---
println!("Tarea {:02} [{:?}] -> Iniciando PARTE {:02}", i, thread::current().id(), j + 1);
calculo_pesado(carga);
}
println!("Tarea {:02} [{:?}] Trabajo finalizado", i, thread::current().id());
}
fn main() {
let inicio_programa = Instant::now();
let mut handles = vec![];
let n_tareas = 10;
let n_partes = 5;
let carga = 50_000_000;
for i in 0..n_tareas {
let handle = thread::spawn(move || ejecutar_tarea(i, n_partes, carga));
handles.push(handle);
}
// Esperar a que todos terminen
for h in handles {
h.join().unwrap();
}
let duracion_total = inicio_programa.elapsed();
println!("--- Todas las tareas han finalizado. ---");
println!("DURACIÓN TOTAL DEL PROGRAMA: {:?}", duracion_total);
}
Salida: (muestra abreviada)
Tarea 01 [ThreadId(3)] -> Requiriendo datos en disco
Tarea 00 [ThreadId(2)] -> Requiriendo datos en disco
Tarea 00 [ThreadId(2)] -> Iniciando PARTE 01
Tarea 02 [ThreadId(4)] -> Requiriendo datos en disco
Tarea 03 [ThreadId(5)] -> Requiriendo datos en disco
Tarea 06 [ThreadId(8)] -> Requiriendo datos en disco
Tarea 04 [ThreadId(6)] -> Requiriendo datos en disco
Tarea 07 [ThreadId(9)] -> Requiriendo datos en disco
Tarea 08 [ThreadId(10)] -> Requiriendo datos en disco
Tarea 09 [ThreadId(11)] -> Requiriendo datos en disco
Tarea 05 [ThreadId(7)] -> Requiriendo datos en disco
Tarea 01 [ThreadId(3)] -> Iniciando PARTE 01
Tarea 00 [ThreadId(2)] -> Requiriendo datos en disco
Tarea 00 [ThreadId(2)] -> Iniciando PARTE 02
Tarea 02 [ThreadId(4)] -> Iniciando PARTE 01
Tarea 03 [ThreadId(5)] -> Iniciando PARTE 01
Tarea 04 [ThreadId(6)] -> Iniciando PARTE 01
Tarea 05 [ThreadId(7)] -> Iniciando PARTE 01
Tarea 01 [ThreadId(3)] -> Requiriendo datos en disco
Tarea 06 [ThreadId(8)] -> Iniciando PARTE 01
Tarea 01 [ThreadId(3)] -> Iniciando PARTE 02
Tarea 07 [ThreadId(9)] -> Iniciando PARTE 01
Tarea 00 [ThreadId(2)] -> Requiriendo datos en disco
Tarea 00 [ThreadId(2)] -> Iniciando PARTE 03
Tarea 08 [ThreadId(10)] -> Iniciando PARTE 01
Tarea 02 [ThreadId(4)] -> Requiriendo datos en disco
Tarea 09 [ThreadId(11)] -> Iniciando PARTE 01
Tarea 02 [ThreadId(4)] -> Iniciando PARTE 02
Tarea 03 [ThreadId(5)] -> Requiriendo datos en disco
Tarea 03 [ThreadId(5)] -> Iniciando PARTE 02
Tarea 04 [ThreadId(6)] -> Requiriendo datos en disco
Tarea 05 [ThreadId(7)] -> Requiriendo datos en disco
Tarea 01 [ThreadId(3)] -> Requiriendo datos en disco
Tarea 06 [ThreadId(8)] -> Requiriendo datos en disco
Tarea 01 [ThreadId(3)] -> Iniciando PARTE 03
Tarea 00 [ThreadId(2)] -> Requiriendo datos en disco
Tarea 00 [ThreadId(2)] -> Iniciando PARTE 04
Tarea 07 [ThreadId(9)] -> Requiriendo datos en disco
Tarea 08 [ThreadId(10)] -> Requiriendo datos en disco
Tarea 04 [ThreadId(6)] -> Iniciando PARTE 02
Tarea 09 [ThreadId(11)] -> Requiriendo datos en disco
Tarea 02 [ThreadId(4)] -> Requiriendo datos en disco
Tarea 02 [ThreadId(4)] -> Iniciando PARTE 03
Tarea 05 [ThreadId(7)] -> Iniciando PARTE 02
Tarea 06 [ThreadId(8)] -> Iniciando PARTE 02
Tarea 03 [ThreadId(5)] -> Requiriendo datos en disco
Tarea 01 [ThreadId(3)] -> Requiriendo datos en disco
Tarea 00 [ThreadId(2)] -> Requiriendo datos en disco
Tarea 00 [ThreadId(2)] -> Iniciando PARTE 05
Tarea 01 [ThreadId(3)] -> Iniciando PARTE 04
Tarea 07 [ThreadId(9)] -> Iniciando PARTE 02
Tarea 03 [ThreadId(5)] -> Iniciando PARTE 03
Tarea 08 [ThreadId(10)] -> Iniciando PARTE 02
Tarea 04 [ThreadId(6)] -> Requiriendo datos en disco
Tarea 09 [ThreadId(11)] -> Iniciando PARTE 02
Tarea 04 [ThreadId(6)] -> Iniciando PARTE 03
Tarea 02 [ThreadId(4)] -> Requiriendo datos en disco
Tarea 02 [ThreadId(4)] -> Iniciando PARTE 04
Tarea 05 [ThreadId(7)] -> Requiriendo datos en disco
Tarea 06 [ThreadId(8)] -> Requiriendo datos en disco
Tarea 05 [ThreadId(7)] -> Iniciando PARTE 03
Tarea 06 [ThreadId(8)] -> Iniciando PARTE 03
Tarea 03 [ThreadId(5)] -> Requiriendo datos en disco
Tarea 07 [ThreadId(9)] -> Requiriendo datos en disco
Tarea 00 [ThreadId(2)] Trabajo finalizado
...
--- Todas las tareas han finalizado. ---
DURACIÓN TOTAL DEL PROGRAMA: 29.79427011s
La salida evidencia una ejecución altamente intercalada entre hilos, lo que confirma que el programa aprovecha la concurrencia para avanzar varias tareas a la vez, aunque no necesariamente en paralelo físico completo. Se observa también que unas tareas entran en espera por I/O mientras otras continúan ejecutándose, lo cual mejora el aprovechamiento del CPU. Sin embargo, el tiempo total no disminuye de forma proporcional al número de threads, porque el rendimiento final depende del scheduler y de los recursos reales del hardware.
Problema de lectores y escritores en Rust
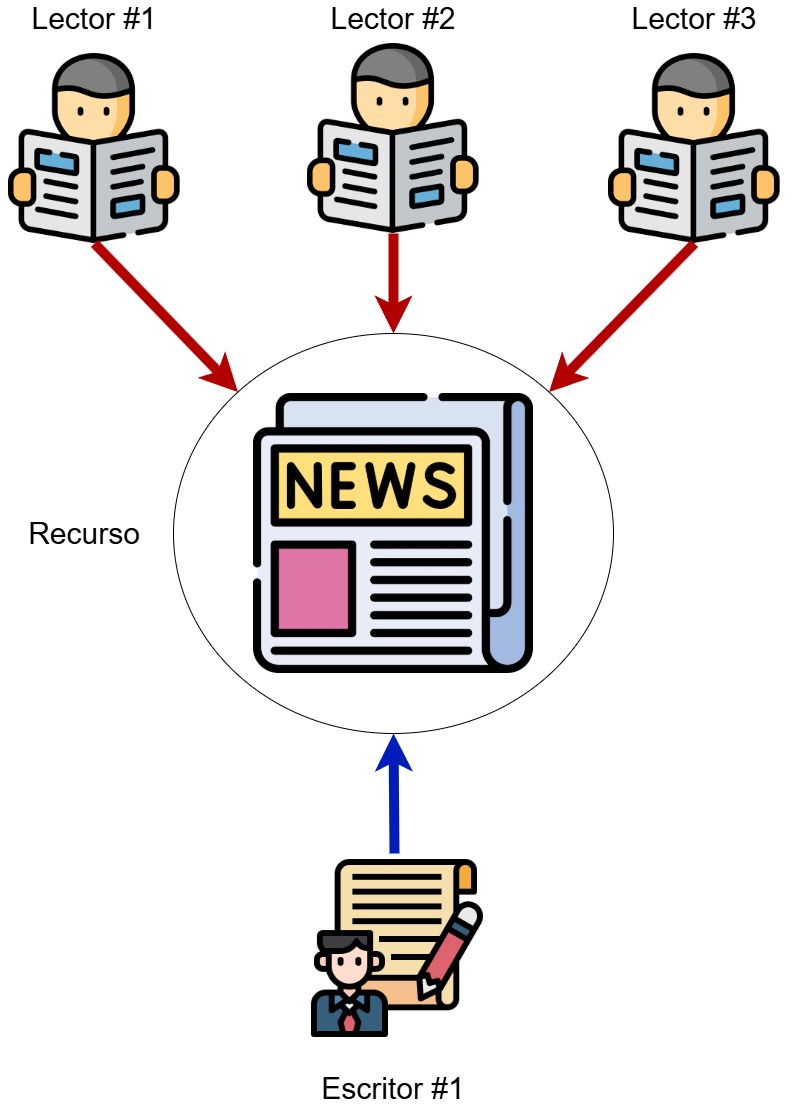
El problema de lectores y escritores es un problema clásico en programación concurrente. Tenemos un conjunto de hilos que quieren leer un dato, así como otro conjunto de hilos que quiere modificarlo. Si un hilo modifica el dato mientras otro está leyéndolo se producirá una lectura stale. También se pueden producir errores por operaciones realizadas en una secuencia incorrecta entre los escritores. En este ejemplo tenemos un solo escritor y múltiples lectores. El acceso se serializa para todos mediante un Mutex. Cada lector lee el valor protegido por el Mutex mientras que el escritor lo modifica sumándole 10 cada vez que obtiene acceso a él. El Arc permite que el mismo recurso sea compartido por todos los hilos de forma segura
use std::sync::{Arc, Mutex};
use std::thread;
use std::time::Duration;
fn lector(id: usize, dato: Arc<Mutex<i32>>) {
for _ in 0..3 {
let num = dato.lock().unwrap();
println!("Lector {} lee valor: {}", id, *num);
thread::sleep(Duration::from_millis(500));
}
}
fn escritor(dato: Arc<Mutex<i32>>) {
for _ in 1..=3 {
{
let mut num = dato.lock().unwrap();
*num += 10;
println!("Escritor modifica valor a: {}", *num);
}
thread::sleep(Duration::from_millis(700));
}
}
fn main() {
let dato = Arc::new(Mutex::new(0));
let mut handles = vec![];
// Lectores
for i in 0..3 {
let dato_clonado = Arc::clone(&dato);
let handle = thread::spawn(move || lector(i, dato_clonado));
handles.push(handle);
}
// Escritor
let dato_clonado = Arc::clone(&dato);
let handle_escritor = thread::spawn(move || escritor(dato_clonado));
handles.push(handle_escritor);
// Esperar todos los hilos
for handle in handles {
handle.join().unwrap();
}
}
Crystal:
Crystal usa hilos llamados fibras para lograr concurrencia. Las fibras se comunican entre sí mediante
canales, como en Go o Clojure, sin tener que recurrir a la memoria compartida o bloqueos.
Cuando se inicia un programa, se activa la fibra principal que ejecutará su código de nivel superior.
Allí, uno puede engendrar (spawn) más fibras.
Los componentes de un programa son:
- Runtime Scheduler, a cargo de ejecutar todas las fibras cuando sea el momento adecuado.
- El bucle de eventos, que es solo otra fibra, está a cargo de tareas asíncronas, como por ejemplo archivos, sockets, pipes, señales y temporizadores.
- Canales, para comunicar datos entre fibras. Runtime Scheduler coordinará fibras y canales para su comunicación.
- Garbage collector: para limpiar la memoria que "ya no se usa".
spawn do
loop do
puts "Hello!"
end
end
sleep 1.second
Este programa imprimirá "¡Hello!" por un segundo y luego saldrá. Esto se debe a que la llamada de espera
programará la fibra principal que se ejecutará en un segundo y luego ejecutará otra fibra "lista para
ejecutarse", que en este caso es la de arriba.
Otra manera seria:
spawn do
loop do
puts "Hello!"
end
end
Fiber.yield
Fiber.yield le dirá al scheduler que ejecute la otra fibra. Esto imprimirá "Hello" hasta los bloques de salida estándar y luego la ejecución continuará con la fibra principal y el programa saldrá.
Creando(spawn) una llamada:
El programa imprime los números del 0 al 9. Se crea un Proc y se invoca pasando I, por lo que el valor se
copia y la fibra engendrada recibe una copia.
i = 0
while i < 10
proc = ->(x : Int32) do
spawn do
puts(x)
end
end
proc.call(i)
i += 1
end
Fiber.yield
La salida es la siguiente:
0
1
2
3
4
5
6
7
8
9
Canales:
Cuando el programa ejecuta una recepción, esa fibra se bloquea y la ejecución continúa con la otra fibra.
Cuando se ejecuta un envió, la ejecución continúa con la fibra que estaba esperando en ese canal.
channel = Channel(Int32).new
spawn do
puts "Before first send"
channel.send(1)
puts "Before second send"
channel.send(2)
end
puts "Before first receive"
value = channel.receive
puts value # => 1
puts "Before second receive"
value = channel.receive
puts value # => 2
La salida es la siguiente:
Before first receive
Before first send
1
Before second receive
Before second send
2
C:
Ejemplo con el juego PacmanAquí, el programa debe poder recibir la entrada teclado del usuario. Pero también, al mismo tiempo, tienes que:
- Calcula los movimientos de los enemigos gracias a la inteligencia artificial.
- Ver los diferentes desplazamientos.
- Actualizar el mapa
int main_loop(IGame *Game, IGui *curse) {
board game;
t_orientation dir;
int k = 0;
while (k == 0) {
dir = curse->get_touch();
if (dir > 4)
return (dir);
k = Game->check_move(dir);
game = Game->get_board();
if (curse->display(game) == -1)
return (0);
}
delete curse;
delete Game;
return (0);
}
Si observamos el código que se muestra, la función get_touch iniciará un hilo que se ocupará de recuperar la entrada del teclado pero no bloqueará el resto del programa: no esperará a recuperar una tecla para continuar.
Ejemplo Comparativo
Suma concurrente
Dado un arreglo de números, queremos sumar todos sus elementos. Utilizaremos programación concurrente para dividir el trabajo entre varios workers y sumar los resultados parciales. Esta solución será implementada en tres lenguajes diferentes: Go, Elixir y Rust. Cada lenguaje tiene sus propias características y formas de manejar la concurrencia. A continuación, se presenta el código para cada uno de estos lenguajes seguido de una tabla comparativa que detalla las diferentes secciones del código y cómo se implementan en cada lenguaje.
Go
package main
import (
"fmt"
"sync"
)
func worker(arr []int, wg *sync.WaitGroup, resultChan chan int) {
defer wg.Done()
sum := 0
for _, num := range arr {
sum += num
}
resultChan <- sum
}
func main() {
arr := []int{1, 2, 3, 4, 5, 6, 7, 8, 9, 10}
numWorkers := 2
chunkSize := len(arr) / numWorkers
resultChan := make(chan int, numWorkers)
var wg sync.WaitGroup
for i := 0; i < numWorkers; i++ {
start := i * chunkSize
end := start + chunkSize
if i == numWorkers-1 {
end = len(arr)
}
wg.Add(1)
go worker(arr[start:end], &wg, resultChan)
}
wg.Wait()
close(resultChan)
totalSum := 0
for sum := range resultChan {
totalSum += sum
}
fmt.Printf("Total Sum: %d\n", totalSum)
}
Elixir
defmodule ConcurrentSum do
def worker(pid, list) do
sum = Enum.sum(list)
send(pid, {self(), sum})
end
def start(list) do
num_workers = 2
chunk_size = div(length(list), num_workers)
pids = for i <- 1..num_workers do
start = (i - 1) * chunk_size + 1
finish = min(start + chunk_size - 1, length(list))
spawn(ConcurrentSum, :worker, [self(), Enum.slice(list, start - 1, finish - start + 1)])
end
receive_results(pids, 0)
end
defp receive_results([], acc) do
IO.puts("Total Sum: #{acc}")
end
defp receive_results(pids, acc) do
receive do
{_, sum} ->
receive_results(tl(pids), acc + sum)
end
end
end
ConcurrentSum.start([1, 2, 3, 4, 5, 6, 7, 8, 9, 10])
Rust
use std::sync::mpsc;
use std::thread;
fn worker(arr: &[i32], tx: mpsc::Sender) {
let sum: i32 = arr.iter().sum();
tx.send(sum).expect("Could not send data!");
}
fn main() {
let arr = vec![1, 2, 3, 4, 5, 6, 7, 8, 9, 10];
let num_workers = 2;
let chunk_size = arr.len() / num_workers;
let (tx, rx) = mpsc::channel();
let mut handles = vec![];
for i in 0..num_workers {
let start = i * chunk_size;
let end = if i == num_workers - 1 {
arr.len()
} else {
start + chunk_size
};
let chunk = arr[start..end].to_vec();
let tx = tx.clone();
let handle = thread::spawn(move || {
worker(&chunk, tx);
});
handles.push(handle);
}
for handle in handles {
handle.join().expect("Thread couldn't join!");
}
let total_sum: i32 = rx.iter().take(num_workers).sum();
println!("Total Sum: {}", total_sum);
}
Tabla Comparativa
| Sección | Go | Elixir | Rust |
|---|---|---|---|
| División del Trabajo |
|
|
|
| Sincronización |
|
|
|
| Recolección de Resultados |
|
|
|